Decision Trees - DT
Non-Parametric Supervised Learning
Overview
Decision trees are used for both classification and regression tasks. A decision tree follows the following structure:

Root Node
Branch
Decision Node
Leaf Node
The root of the decision tree is located at the top center and does not have any incoming branches. Branches then extend to more nodes. If a node is a decision node, it then has additional nodes below it to ultimately end up at a leaf node with no further branching.
These flowcharts provide insight into decision-making allowing for a clear understanding of why a decision was made based on the decision tree the point followed.
Decision trees follow a strategy of divide and conquer by using a "greedy" search to identify the optimal points to split the tree at. Smaller trees make it easier to obtain pure leaf nodes however, as a tree grows in size the purity of the tree is harder to maintain. When this happens, the model can be overfitted which causes inaccuracies in the model.
Entropy & Information Gain
One of the challenges of decision trees is information gain and the impurity of the sample.
Entropy measures the impurities of these values and can be calculated by the following formula:
S = data set the entropy is calculated for
c = classes of set S
p(c) = The proportion of data points that belong to class c to the total number of data points in set S

Entropy values fall between 0 and 1. If all samples in the data set belong to one class, then the entropy would equal 0. If half of the samples are in one class and half are in the other class, entropy will be 1. In order to determine the best value to split on, the attribute with the smallest entropy should be chosen.
Once the entropy is determined, we can then determine the information gained. Information gained is calculated by taking the entropy of the split before minus the entropy after the split on a given attribute. Information gained can be calculated from the following formula:
alpha = represents a specific attribute
Entropy(S) = Entropy of the data set S
|Sv| / |S| = Proportion of values in Sv divided by the total number of values in the dataset
Entropy(Sv) - Entropy of the sub-data set Sv

Gini Impurity
Gini impurity is the probability of accidentally incorrectly classifying a data point. Logically following entropy, if the set S only contains one class, then the impurity is also 0. The lower the impurity score is, the better the split that was made is.

Advantages of DT
-
Easy to interpret results
-
Little to no data preparation required
-
More flexible than other algorithms
Disadvantages of DT
-
Prone to overfitting
-
High variance estimators
-
More costly
Data Prep
For data cleaning, the initial cleaning was completed on the EDA page, the main things completed for this dataset were the renaming of columns for clarity and ease of access.
For decision trees, the one requirement that has to be completed for the data set is to create a training and a test data set. In this portion of the project, the data set being used is the Kaggle migraine data set. The data set contained 400 records that were then split into two distinct independent sets.

Training Set
70% of the data set totaling 280 records.

Testing Set
30% of the data set totaling 120 records.
Code & Results
The decision trees will be coded in R.
The first decision tree takes a look at Migraine Type and then takes the full data set as parameters to predict

From the prediction, the conditions it splits the tree is:
-
Visual < 1
-
Sensory < 1
-
Age >= 26
-
DPF = 1
-
Age < 24
-
Vertigo = 1
-
Location >= 1
From the first tree, interestingly Age did make some pretty big impacts in the tree. It looks like Age determines 3 leaf nodes for migraine types and all three include auras, strange!

Over to the right is the confusion matrix for the test data set.
Overall, the tree did a pretty good job predicting the test data set. It was almost 80% accurate in it's identification of migraine type!

Now let's try taking away some of the parameters based on the GINI impurity scores!
As expected, from the impurity score of Age this would signify we only have 1 class, therefore our tree is just one node! There are only 3 records that fall outside of this classification.
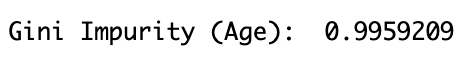


From the PCA tab, exploring the idea of just frequency and duration dictating the type of migraine. Hoping to answer the research question do those factors predict the type of migraine a person will face.
It looks like the conditions that decide where you belong is if you have a frequency >= 5 and a duration >= 2


Sadly, the hypothesis about just duration and frequency predicting the type of migraine was only ~64% accurate with the test set. A larger sample size might have played a part in this, but based on some things learned in the NB tab, sampling didn't seem to boost the accuracy all that much.
Conclusion
For this portion of the project, there weren't a ton of insights gleaned from this particular data set. Having all of the factors in the prediction helps boost the accuracy of the model tremendously. One thing these decision trees did bring to light is that migraines are complex, and there's no straightforward way to predict exactly how a migraine will affect a person. Every person is unique and while one set of symptoms may affect a person X they may not apply at all to person Y.